

Abstract
When we talk about machine learning (ML) or artificial intelligence (AI), the conversation often gravitates toward cutting-edge models, powerful algorithms, and impressive results. However, one critical but often overlooked step plays an equally important role in making all this possible: data preprocessing. While not the most glamorous part of the pipeline, it is arguably the most essential.
Data preprocessing is a vital yet frequently underappreciated phase in the ML/AI workflow. Raw data tends to be messy, incomplete, and unstructured, making it unsuitable for direct use in models. Whether you are dealing with a spreadsheet of customer data, a stream of sensor information from IoT devices, or user reviews from a website, raw data requires significant work before it is ready for modeling. Data preprocessing bridges the gap by transforming this raw data into a clean, organized format that lays the foundation for successful model training. This post will explore the critical role of data preprocessing, highlight key techniques, and discuss emerging trends that are shaping the future of AI and ML.
What Types of Data Power AI and ML?
In the world of AI and ML, data is the foundation upon which all models are built [1]. However, not all data is created equal. Different data types come with unique characteristics and challenges, which require tailored preprocessing techniques to make them usable in AI/ML systems. Understanding these differences is key to effective preprocessing.
Numerical data includes continuous or discrete values like height, temperature, or academic grades. While it is straightforward to work with, it still needs preprocessing to handle scale differences and outliers. Categorical Data represents non-numeric labels that signify categories, such as colors, brands, or species. Encoding techniques are typically used to convert these into a numerical format that algorithms can process. With only two possible values—like 0 or 1—binary data is simpler and often used to represent true/false or presence/absence states. Text data, often unstructured, introduces complexity in preprocessing. Transforming text (e.g., emails, reviews, social media posts) requires tokenization, stopword removal, and vectorization to derive meaningful patterns. Multimedia, such as audio, images, and video, plays a central role in fields like speech recognition and computer vision. These data types demand specialized preprocessing steps like spectrogram analysis or image augmentation.
The structure of data also varies. Some arrive neatly in tabular form, while other types, like time-series, graph or geospatial data, introduce additional complexities. Time-series data, for example, has a temporal dependency that must be managed during preprocessing. Meanwhile, graph data represents relationships between entities, essential in applications like social networks or recommendation systems. Geospatial data (e.g., GPS coordinates) adds another layer of spatial context that can inform everything from logistics planning to environmental monitoring.
Today’s data landscape is increasingly complex and multimodal, often blending sensor readings from IoT devices with visual content like images and videos. As ML models grow more sophisticated, preprocessing techniques must evolve in tandem—capable of handling this diversity to ensure that every data type is accurately interpreted and meaningfully integrated.
How AI/ML Algorithms Work with Datasets
With a grasp of the different data types used in AI and ML, the next step is to consider how these data types are handled within a typical ML pipeline [2]. The journey from raw data to meaningful insights or predictions starts long before the model. It begins with data preprocessing, which ensures that the data is clean, organized, and in the correct format for the algorithm to process effectively. Once the data is collected, it is cleaned and organized. After preprocessing, the data is split into training and testing sets. The training data helps the model learn patterns and relationships, while the test data serves as an objective benchmark to evaluate how well the model generalizes to new, unseen inputs.
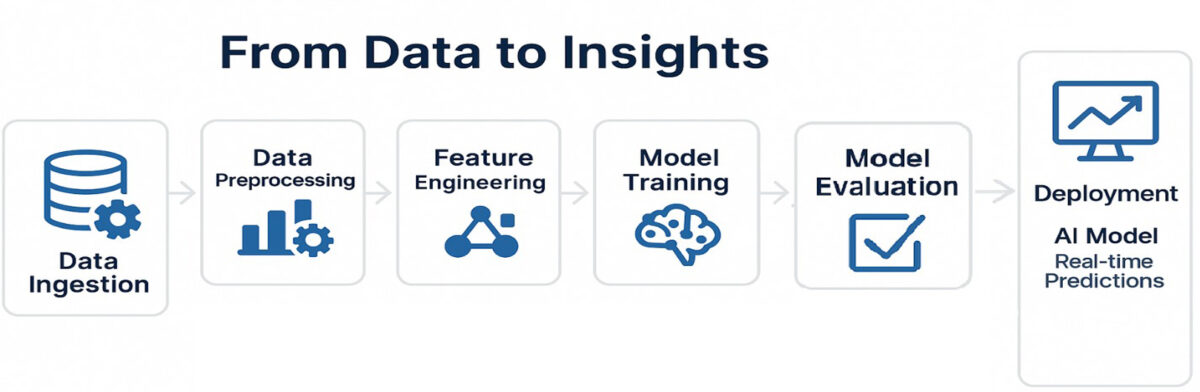
The Importance of Data Quality in AI/ML
At the core of every successful AI/ML model is the principle: the quality of the input data directly impacts the quality of the model’s output. No matter how sophisticated a ML algorithm may be, it cannot overcome poor-quality data. High-quality data forms the backbone of accurate, fair, and reliable AI systems. When that foundation is compromised—whether through errors, inconsistencies, or imbalances—the consequences can ripple throughout the entire model, leading to biased, misleading, or simply incorrect results [3, 4, 5].
One of the most common pitfalls is imbalanced data, where certain categories or classes are significantly underrepresented [6]. In such cases, a model may learn to favor the dominant class, achieving deceptively high accuracy while failing to detect or predict the minority class—an issue that can be particularly problematic in applications like fraud detection or medical diagnosis.
Another challenge arises from feature scale differences. When features vary widely in magnitude—such as combining income in the thousands with age in double digits—some algorithms, especially those that rely on distance calculations like k-nearest neighbors or support vector machines, may skew results toward the more dominant features. Without proper scaling or normalization, the model’s understanding of the data can become distorted.
Noise—whether in the form of irrelevant, incorrect, or inconsistent data points—can further cloud the learning process. Instead of discovering meaningful patterns, a model might latch onto random fluctuations, leading to overfitting or unreliable predictions [3]. Similarly, missing data introduces uncertainty. Whether it is empty cells in a spreadsheet or absent sensor readings, these gaps can significantly reduce a model’s ability to generalize.
Outliers present yet another complication. These extreme values, whether the result of input errors or genuine anomalies, can exert undue influence on the model, particularly in regression tasks where they can skew predictions or increase error metrics [7]. And in more domain-specific contexts—such as text or image-based applications—data quality issues can take the form of misspellings, grammatical errors, or low-resolution images. In fields like natural language processing or computer vision, even small imperfections can dramatically reduce model performance.
Key Data Preprocessing Practices and Techniques
Confronting these issues early—during the preprocessing stage—is not just advisable; it is essential. Cleaning, correcting, and preparing the data ensures that models are trained on a stable, representative foundation. Without this diligence, even the most advanced algorithms will struggle to deliver meaningful results. Below are some of the key practices and techniques involved in data preprocessing.
1. Data Cleaning
The first step in preparing data for ML is to identify and correct errors or inconsistencies. This includes:
- Handling missing data, often through imputation techniques such as filling gaps with the mean, median, or using regression-based methods to estimate missing values.
- Noise reduction, which can take different forms depending on the data type. In textual data, this might involve removing stopwords or correcting spelling errors; for image data, applying denoising filters can help improve quality and clarity [8].
- Outlier detection, using statistical approaches like the Z-score or Interquartile Range, helps identify and manage data points that may distort model training [7].
2. Data Transformation
Once cleaned, the data must be formatted appropriately for ML models. Key transformation techniques include:
- Normalization and standardization, which bring features onto a common scale, preventing algorithms—especially those based on distance metrics—from being skewed by feature magnitude.
- Encoding categorical variables, since most algorithms require numerical input. Techniques like One-Hot Encoding and Label Encoding translate categorical data into machine-readable numerical formats [9].
- Image transformations include a variety of preprocessing steps such as resizing, color space conversion and normalization of pixel values. These transformations prepare images for consistent input into ML/AI models.
- Text transformations, beyond encoding, may involve stemming or lemmatization, removing special characters, and converting all text to lowercase. More advanced pipelines might also include named entity recognition or dependency parsing to extract syntactic and semantic meaning before converting the text into vectors [10].
3. Feature Engineering
Feature engineering is the art of crafting the most informative variables for the model. It includes:
- Creating new features by combining or decomposing existing ones to reveal hidden trends—such as extracting day, month, or seasonality from timestamps to detect temporal patterns [11].
- Text vectorization transforms unstructured text into numerical features. These types of methods allow models to capture not just word frequency, but also semantic relationships [10].
- Image feature extraction includes techniques like edge, histogram of oriented gradients, or color histograms to capture spatial and visual information. More advanced workflows may involve pre-trained convolutional neural networks (CNNs) to extract deep features without training from scratch [12].
- Time-series feature engineering often involves generating lag features, rolling averages, trend indicators, or Fourier transforms to highlight seasonal patterns and long-term trends [11]. These engineered features help models understand how current values relate to past events, which is crucial for forecasting tasks.
- Audio feature extraction includes techniques like Mel-frequency cepstral coefficients, spectral contrast, or zero-crossing rate, which are commonly used in speech recognition and music classification. These features convert raw waveforms into a more structured representation of sound [13].
4. Data Reduction
As datasets grow in size and complexity, reducing them without sacrificing critical information becomes necessary. This involves:
- Feature selection, which identifies the most relevant variables using statistical tests, wrapper methods, or embedded techniques [14, 15].
- Dimensionality reduction, such as Principal Component Analysis, which condenses large feature sets into fewer components that retain most of the information.
5. Data Augmentation
In cases where data is limited or class distribution is uneven, data augmentation expands the dataset by generating new samples. The specific methods used depend on the type of data involved.
- Image augmentation, through transformations like rotation, flipping, or zooming, introduces variability and prevents overfitting in computer vision tasks [16].
- Text augmentation, using methods like back-translation or paraphrasing, generates alternative phrasings to increase data diversity in natural language processing tasks [17].
6. Handling Imbalanced Data
When some classes are overrepresented, models may struggle to learn minority patterns. Preprocessing can address this through:
- Oversampling, such as SMOTE (Synthetic Minority Over-sampling Technique), which creates synthetic examples of underrepresented classes [18].
- Undersampling, which eliminates instances of the majority class [19].
- Cost-sensitive learning, which penalizes the misclassification of minority classes more heavily during training, helping the model focus on harder-to-detect categories [19].
Challenges in Data Preprocessing
Despite its importance, data preprocessing comes with its own set of difficulties that can impact the effectiveness of the entire AI/ML pipeline.
- Complexity and Time Consumption
Preprocessing can be a labor-intensive process, especially for large datasets. From cleaning and transformation to feature selection, these tasks require careful planning and considerable computational resources. Leveraging parallel processing or distributed systems can help alleviate the time burden.
- Data Leakage
One of the most critical pitfalls is data leakage—when information from outside the training dataset inadvertently influences the model. This leads to inflated performance during training and poor generalization in real-world use. Avoiding leakage requires strict separation of training and testing data and careful feature engineering that doesn’t incorporate future information [20].
- Scalability
As datasets increase in volume, velocity, and variety, traditional tools often fall short. Preprocessing large-scale data requires scalable architectures and technologies—such as distributed frameworks or cloud-based solutions—that can manage the growing demand for speed and storage.
- Ethical Considerations
Preprocessing also raises ethical concerns. If biases related to race, gender, or socioeconomic status exist in the raw data, preprocessing may inadvertently reinforce them. Ensuring fairness and transparency involves identifying potential sources of bias, anonymizing sensitive data, and making deliberate efforts to build more equitable datasets.
- Loss of Information
There is always a risk that important information may be lost in the process of cleaning or transforming data. Removing outliers or imputing missing values can sometimes mask meaningful patterns. Striking the right balance between noise reduction and information preservation is a delicate yet crucial task.
- Domain Knowledge Dependence
Effective preprocessing often depends on deep domain knowledge. Understanding what constitutes an outlier, selecting appropriate transformations, or interpreting feature importance requires expertise that goes beyond generic techniques. Collaboration with domain experts is therefore vital to make informed preprocessing decisions that truly reflect the nature of the data.
The Future of Data Preprocessing
As AI and ML continue to advance, the field of data preprocessing is undergoing a parallel transformation. With datasets growing larger, more complex, and increasingly diverse, the demand for smarter, faster, and more adaptive preprocessing techniques is intensifying. Several emerging trends are poised to redefine how we prepare data for the next generation of intelligent systems.
One of the most significant shifts is the rise of automated data preprocessing. Platforms such as Google Cloud AutoML, Microsoft Azure AutoML, and H2O.ai are making it possible to streamline routine preprocessing tasks—from missing value imputation to feature selection—enabling non-experts to engage with ML workflows. This automation not only accelerates model development but also frees up data scientists to focus on more strategic and high-impact challenges.
Simultaneously, the integration of diverse and multimodal data sources is becoming the norm. From combining text and images to incorporating sensor data from IoT devices, preprocessing now requires sophisticated pipelines capable of handling varied data types [21]. The ability to merge and align these formats is critical for building robust models that can operate in dynamic, real-world environments.
Another critical trend is the move toward real-time and streaming data preprocessing, particularly in domains like finance, healthcare, and autonomous systems. Low-latency data pipelines, powered by distributed event streaming platforms and edge computing, are enabling models to process and respond to data as it arrives—transforming AI systems from reactive tools into proactive decision-makers.
To address challenges like data scarcity and privacy, the use of synthetic data is becoming more prevalent. Techniques such as Generative Adversarial Networks (GANs) allow for the creation of realistic, artificial datasets that can augment limited real-world data, balance class distributions, and enable safer experimentation without compromising sensitive information [22].
In this context, advanced feature engineering and representation learning are also gaining prominence. Deep learning architectures such as autoencoders and transformers are reducing the reliance on manual feature crafting by learning abstract, high-quality representations directly from raw data [23]. These methods not only simplify preprocessing but also help uncover complex, non-linear patterns that might be missed with traditional techniques.
Privacy and ethics are also shaping the future of preprocessing. Approaches like differential privacy and federated learning enable models to train on decentralized data without exposing individuals’ information. These methods promote compliance with data protection regulations while reinforcing trust in AI systems [24].
Moreover, hybrid cloud and on-premise strategies are emerging to balance scalability with security. While cloud platforms offer computational power and flexibility, on-premise solutions ensure control over sensitive data—making hybrid architectures a preferred choice for organizations navigating regulatory constraints.
Finally, as regulatory scrutiny increases, transparent and auditable preprocessing workflows are becoming essential. Data lineage tracking, reproducible pipelines, and clear documentation of preprocessing decisions will not only facilitate compliance but also promote accountability and trust in AI systems [25].
Together, these innovations signal a future where data preprocessing is not just a preparatory step, but a dynamic and intelligent process in its own right—one that is critical to building scalable, responsible, and high-performing AI.
Conclusion
Data preprocessing remains the cornerstone of any successful AI/ML pipeline. By addressing data quality issues early and applying the right transformations, we lay the foundation for accurate, efficient, and ethical models. As AI continues to evolve, the future of data preprocessing will be pivotal in unlocking the full potential of machine learning and artificial intelligence.
References
[1] N. Prasad. Data Quality and Preprocessing. In Introduction to Data Governance for Machine Learning Systems: Fundamental Principle, Critical Practices, and Future Trends. 109-223.
[2] E. Alpaydin. Introduction to machine learning. MIT press, 2020.
[3] M. Dudjak and G. Martinović. An empirical study of data intrinsic characteristics that make learning from imbalanced data difficult. Expert Systems with Applications, 182:115297, 2021.
[4] P. Skryjomski and B. Krawczyk. Influence of minority class instance types on smote imbalanced data oversampling. Proceedings of the 1st International Workshop on Learning with Imbalanced Domains: Theory and Applications, 7–21, 2017.
[5] V. López, A. Fernández, S. García, V. Palade i F. Herrera. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Information Sciences, 250:113–141, 2013.
[6] A. Fernández, S. García, M. Galar, R. C. Prati, B. Krawczyk i F. Herrera. Learning from imbalanced data sets, vol. 11. Springer, 2018.
[7] K. Singh and S. Upadhyaya. Outlier detection: applications and techniques. International Journal of Computer Science Issues, 9(1):307., 2012.
[8] S. Gupta and A. Gupta. Dealing with noise problem in machine learning data-sets: A systematic review. Procedia Computer Science, 161:466–474, 2019.
[9] E. Poslavskaya and A. Korolev. Encoding categorical data: Is there anything’hotter’than one-hot encoding? arXiv preprint arXiv:2312.16930, 2023.
[10] D. Rani, R. Kumar and N. Chauhan. Study and comparison of vectorization techniques used in text classification. International Conference on Computing Communication and Networking Technologies (ICCCNT), 1-6., 2022.
[11] G. Dong and H. Liu. Feature engineering for machine learning and data analytics. CRC Press, 2018.
[12] G. Kumar and P.K. Bhatia. A detailed review of feature extraction in image processing systems. 4th International conference on advanced computing & communication technologies, 5-12, 2014.
[13] D. Moffat, D. Ronan and J.D. Reiss. An evaluation of audio feature extraction toolboxes. 201
[14] J. Tang, S. Alelyani i H. Liu. Feature selection for classification: A review. Data Classification: Algorithms and Applications, 37, 2014.
[15] A. Jović, K. Brkić i N. Bogunović. A review of feature selection methods with applications. Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), 1200–1205, 2015.
[16] C. Shorten and T.M. Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of big data, 6(1):1-48, 2019.
[17] C. Shorten, T.M. Khoshgoftaar and B. Furht. Text data augmentation for deep learning. Journal of big data, 8(1):101, 2021.
[18] N. V. Chawla, K. W. Bowyer, L. O. Hall i W. P. Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16:321–357, 2002.
[19] G. Haixiang, L. Yijing, J. Shang, G. Mingyun, H. Yuanyue i G. Bing. Learning from class-imbalanced data: Review of methods and applications. Expert Systems with Applications, 73:220–239, 2017.
[20] M.A. Bouke, S.A. Zaid and A. Abdullah. Implications of data leakage in machine learning preprocessing: a multi-domain investigation. 2024.
[21] T. Baltrušaitis, C. Ahuja and L.P. Morency. Multimodal machine learning: A survey and taxonomy. IEEE Transactions on pattern analysis and machine intelligence, 41(2):423-443, 2018.
[22] I. Goodfellow et al. Generative adversarial networks. Communications of the ACM, 63(11):139-144, 2020.
[23] A.D. Dhaygude et al. Deep learning approaches for feature extraction in big data analytics. 10th IEEE Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering, 10:964-969, 2022.
[24] A. El Ouadrhiri and A. Abdelhadi. Differential privacy for deep and federated learning: A survey. IEEE Access, 10:22359-22380.
[25] S. Chundru. Leveraging AI for Data Provenance: Enhancing Tracking and Verification of Data Lineage in FATE Assessment. International Journal of Inventions in Engineering & Science Technology, 7(1):87-104, 2021.
Author
Mario Dudjak, PhD
Text is partially generated by artificial intelligence