

In recent years, Large Language Models (LLMs) such as Generative Pre-Training (GPT) [1], Bidirectional Encoder Representations from Transformers (BERT) [2], Large Language Model Meta AI (LLAMA) [3], Pathways Language Model (PaLM) [4], Enhanced Representation through Knowledge Integration (ERNIE) [5], and Gemini [6] have become increasingly popular. These powerful tools are revolutionizing text generation and summarization, language translation, customer support, code generation, sentiment analysis, and more. In fact, LLMs represent one of the most significant technological breakthroughs of the last decade.
But how did it all start?
The Origins of the LLMs
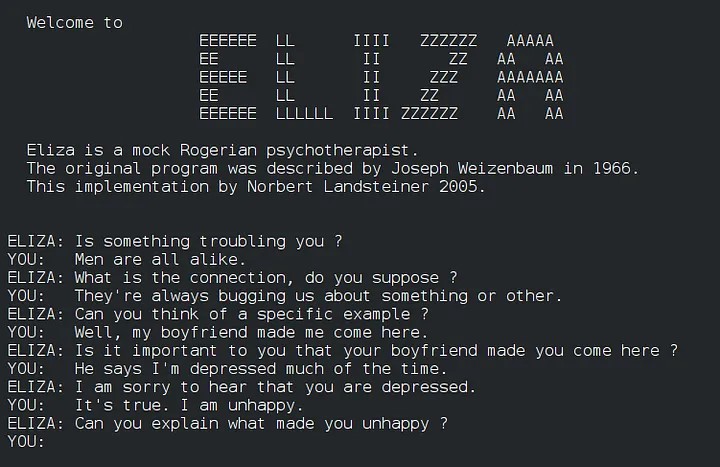
The history of LLMs began in the 1950s, when researchers at IBM and Georgetown University launched a project to develop a system that could automatically translate Russian phrases into English. This pioneering project laid the foundation for Natural Language Processing (NLP), an important branch of Artificial Intelligence (AI) from which LLMs have evolved. The first major breakthrough in NLP came in the 1960s with the development of ELIZA, the world’s first chatbot, by Joseph Weizenbaum at the MIT AI Laboratory. ELIZA simulated conversation, albeit to a limited extent, using pattern matching and script-based processing, particularly through its “doctor” script, which mimicked a Rogerian psychotherapist.
In the late 1980s and early 1990s, the introduction of statistical models revolutionized NLP by relying on the statistical properties of real text rather than strict rules. Notable among these was the N-gram model [7], which was used in Google’s PageRank algorithm in 1996. The rise of deep learning in NLP began in 1986 with the Recurrent Neural Network (RNN) [8], which processes data sequences by using information from previous steps to inform the current step, much like how we understand a story better by remembering what happened earlier in the story. This allows RNNs to capture patterns and dependencies over time, making them effective for tasks like language modeling and time series prediction. To overcome the limitations of RNNs, especially for long sentences, Long Short-Term Memory (LSTM) [9] networks were proposed in 1997. LSTMs are designed to remember information over extended text lengths, tackling the vanishing gradient problem faced by traditional RNNs. However, there were still problems with processing longer sentences as the LSTMs attempted to compress all sentence details into a single fixed-size context vector. A new approach was needed, which led to the introduction of the attention mechanism in 2014 [10]. This mechanism allowed models to focus on specific parts of the input sequence when generating each element of the output sequence. By assigning different weights to different input elements, the attention mechanism dynamically highlights the most relevant parts of the input, improving the handling of long sequences and complex dependencies. Parallel with the development of the attention mechanism, in 2013, Tomas Mikolov and his colleagues at Google introduced the Word2Vec algorithm [11], a neural network model for creating word embeddings. These dense vector representations captured semantic relationships between words based on their context in a large text corpus. The foundation for modern LLMs was laid in 2017 with the publication of the paper “Attention is All You Need” by Vaswani and his team at Google [12]. This paper introduced the transformer architecture, the cornerstone of today’s powerful LLMs.
What does LLM actually mean?
Essentially, an LLM is a sophisticated AI system that is capable of performing a wide range of language-related tasks by leveraging its enormous computing power and extensive training on large datasets. The term “large” refers to the scale and size of the model parameters and the amount of data on which the model has been trained. For example, a GPT-4 model consists of 1.76 trillion parameters and is trained on approximately 10 trillion words. The term “language” refers to the model’s ability to understand and generate human language. The term “model” refers to a mathematical and computational representation that is used to understand and predict the next word in a sentence to produce coherent text or to understand the context and meaning of text.
How does LLM work?
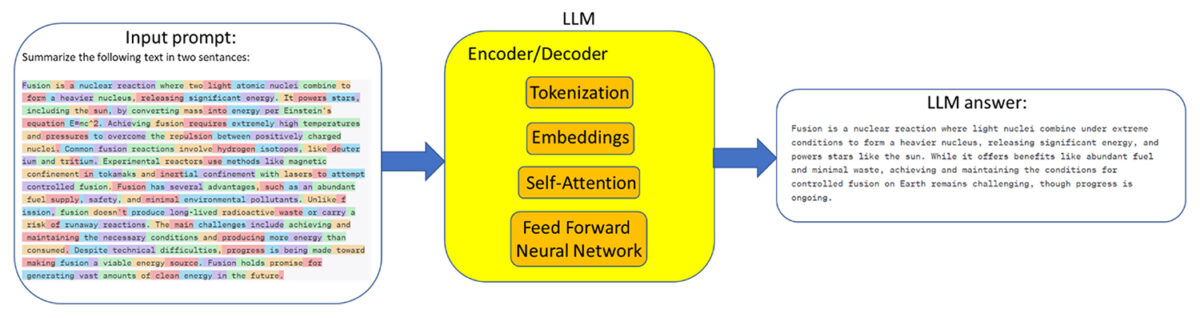
LLM performs several steps to generate output text data from the input text. In the pre-processing phase, the input words are tokenized. During tokenization, the text is broken down into smaller units, so-called tokens. These tokens can be words, sub-words, characters or other meaningful units. Tokenization is a crucial step because it converts the raw text into a format that the model can process. After tokenization, embedding is performed for each token, without paying attention to their relationship in the sentence. Embeddings are the representations of tokens, such as sentences, paragraphs or documents, in a high-dimensional vector space, where each dimension corresponds to a learned feature or attribute of the language. In addition, positional encodings are added to the input embeddings to provide information about the order of words, since the self-attention mechanism alone does not take word positions into account. Modern, high-performance LLMs are based on the transformer neural network architecture. Like RNN and LSTM, a transformer neural network is based on an encoder-decoder system, but greatly enhanced by the self-attention mechanism and associated parallel processing. The self-attention mechanism allows the model to weigh the importance of different words in a sentence when making predictions. It allows each word in a sentence to consider every other word and decide how important each word is to understanding the overall meaning. It’s like each word asking all other words how relevant they are to its own context, and then combining this information to create a richer understanding of the sentence. The self-attention mechanism is inherently parallelizable, as each position in the sequence (each word) is considered independently of all other positions. This means that the computation for each position does not depend on the others, so these operations can be performed simultaneously by a method called multi-head attention. The goal of the attention layer is to capture the contextual relationships between the different words in the input sentence.
How are LLMs trained?
Training an LLM involves three steps and requires significant computational resources. The first step involves self-supervised learning, where a large amount of unlabeled data is fed into the model to learn different language patterns. Self-supervised learning is a type of machine learning in which the model learns from unlabeled data by creating its own labels. The main goal of this step is to learn to predict the next word in the sentence based on the other words. For example, if we give the model the sentence “The basketball is played with _____” and ask the model to predict the next word, after self-supervised learning the model will learn that the missing word is “ball”. The second step in the process of LLM learning, also called fine-tuning, is related to supervised learning, in which a model is trained to follow instructions. Fine-tuning involves training the pre-trained LLM on a specific, labeled data set to improve its performance on specific tasks. Supervised learning is used in this phase, where the model is provided with input-output pairs and learns to match the inputs to the correct outputs. Fine-tuning can be applied to tasks such as sentiment analysis, question answering, named entity recognition and others. For example, in a sentiment analysis task, the data set might contain sentences labeled as “positive” or “negative”. So, if we provide an LLM sentence “It’s sunny today.” for sentiment analysis, it classifies this sentence as positive according to the labeled data provided to LLM during supervised learning. The third stage of LLM learning is reinforcement learning with human feedback. This step was proposed by the Open AI team. In this step, human raters provide feedback on the generated text, which is converted into rewards. This feedback loop helps the model learn to generate more useful and accurate answers.
What are LLMs used for?
LLMs are used for a wide range of NLP tasks. Their adaptability and ability to understand and generate human-like text make them invaluable in various fields. One main application of LLMs is in text generation, where they produce coherent and contextually appropriate text based on a given prompt, which is useful in creative writing, article writing and story completion. In addition, LLMs are used in machine translation to improve the accuracy and fluency of translations in services such as Google Translate. Another important application is text summarization, where LLMs create concise summaries of long documents, making it easier to extract key information from lengthy texts such as research papers or news articles. LLMs also support chatbots and virtual assistants that understand and respond to user queries in a natural and engaging way, such as customer service bots and personal assistants like Siri and Alexa. When answering questions, these models can provide answers based on context or a larger corpus of text, which is beneficial for search engines and information retrieval systems. In addition, LLMs assess the sentiment or emotional tone of a text, helping with social media monitoring, customer feedback analysis and market research. They also identify and classify entities such as names, dates and locations in text, facilitating information extraction and organization through named entity recognition (NER). In text classification, LLMs categorize text into predefined classes, which is essential for spam detection, topic categorization and content moderation. In the area of code generation, these models can generate code snippets or complete programs from natural language descriptions, supporting software development and automated coding tools. Finally, LLMs create personalized content and recommendations based on user preferences and behaviour, improving user engagement and experience on digital platforms. Other types of LLMs, known as multimodal LLMs, are advanced AI systems that can process and integrate multiple types of data such as text, images, audio and video. These models leverage the strengths of different neural network architectures to understand and generate content across different modalities, enabling more comprehensive and contextualized results. By analyzing multiple forms of data simultaneously, multimodal LLMs can perform complex tasks such as labelling images, answering visual questions and generating descriptive text from video. They are designed to mimic human-like understanding, making them highly effective in applications that require a fusion of sensory inputs. The integration of different types of data improves the models’ ability to provide more accurate, relevant and nuanced responses.
What are the drawbacks of LLMs?
LLMs have changed NLP, but they also have significant drawbacks. A major ethical problem is the perpetuation and reinforcement of biases present in their training data, leading to discriminatory results. In addition, LLMs hallucinations can lead to the generation of convincing but false information, creating the risk of spreading misinformation. LLM hallucination refers to the phenomenon where LLMs generate text that is plausible-sounding but factually incorrect or nonsensical. This occurs because the model is predicting text based on patterns in the training data rather than understanding or verifying the factual accuracy of the information. The automation capabilities of LLMs threaten job displacement and skills obsolescence in areas such as customer service and content creation. The legal framework is lagging behind the rapid development of LLMs, leading to regulatory challenges and unresolved intellectual property rights issues for AI-generated content. The environmental impact of LLMs is significant due to the high energy consumption required for training and deployment, contributing to carbon emissions. Another critical issue is privacy, as these models are trained on large datasets that may contain sensitive information, raising privacy and consent concerns. The financial costs of developing, training and maintaining LLMs are significant and often limit access to them for larger companies. The efficient operation of LLMs requires advanced hardware and continued investment in infrastructure and technical expertise, which presents further obstacles. Finally, the lack of transparency of LLMs, which act as “black boxes”‘, makes accountability and trust difficult and highlights the need for clearer decision-making processes. Addressing these challenges is critical to the responsible and equitable use of LLMs.
Conclusion
LLMs represent a significant technological breakthrough, revolutionizing NLP with applications in text generation, machine translation and more. Starting from foundational work in the 1950s, LLMs have evolved through various stages, including the introduction of statistical models and deep learning techniques such as RNNs and transformers. Today, their capabilities include not only the generation of coherent text, but also language translation, document summarization and the enhancement of chatbots and virtual assistants. Despite their transformative potential, LLMs also have significant drawbacks. They can perpetuate biases, hallucinate, spread misinformation and displace jobs, creating ethical and social challenges. In addition, the high energy consumption required to operate them has a significant impact on the environment. Privacy concerns also arise from the extensive data sets used for training, while the high development and infrastructure costs present financial and access barriers. The lack of transparency in decision-making processes makes accountability and trust difficult. Balancing the immense benefits of LLMs with its potential risks will be key to realizing its full potential for the future.
References:
- A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” OpenAI, 2018. [Online]. Available: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
- J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, 2019, pp. 4171-4186. [Online]. Available: https://arxiv.org/abs/1810.04805
- H. Touvron et al., “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023. [Online]. Available: https://arxiv.org/abs/2302.13971
- A. Chowdhery et al., “PaLM: Scaling language modeling with pathways,” arXiv preprint arXiv:2204.02311, 2022. [Online]. Available: https://arxiv.org/abs/2204.02311
- Y. Sun et al., “ERNIE: Enhanced representation through knowledge integration,” arXiv preprint arXiv:1904.09223, 2019. [Online]. Available: https://arxiv.org/abs/1904.09223
- “Google’s Gemini: Setting new benchmarks in language models,” SuperAnnotate, Jun. 2024. [Online]. Available: https://www.superannotate.com/blog/google-gemini-ai. [Accessed: 29-Jun-2024].
- S. Katz, “Estimation of probabilities from sparse data for the language model component of a speech recognizer,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 35, no. 3, pp. 400-401, Mar. 1987, doi: 10.1109/TASSP.1987.1165125.
- D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back-propagating errors,” Nature, vol. 323, pp. 533-536, 1986, doi: 10.1038/323533a0 [Online]. Available:.https://gwern.net/doc/ai/nn/1986-rumelhart-2.pdf
- S. Hochreiter and J. Schmidhuber, “c, vol. 9, no. 8, pp. 1735-1780, 1997, doi: 10.1162/neco.1997.9.8.1735. [Online]. Available: https://www.researchgate.net/publication/13853244_Long_Short-term_Memory
- D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” CoRR, vol. abs/1409.0473, 2014.[Online]. Available: https://arxiv.org/abs/1409.0473
- T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,”, International Conference on Learning Representations 2013, arXiv preprint arXiv:1301.3781, 2013. [Online]. Available: https://arxiv.org/abs/1301.3781
- A. Vaswani et al., “Attention is all you need,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017, pp. 5998-6008. [Online]. Available: https://arxiv.org/abs/1706.03762
Author
Prof. Marijan Herceg, PhD
Text and/or images are partially generated by artificial intelligence